Have you ever felt the frustration of not being understood by the search box of a webpage? Well, you are not alone. This is a usual symptom of search engines that don’t rely on the power of semantic similarity through embeddings—an innovative tool that is often overlooked in the current AI landscape.
This post aims to explain to a non-technical audience what embeddings are, how a business can benefit from them, and how we leverage them at fjord. On that note, I’ll be skipping the fancy but scary math behind it, so apologies in advance to my fellow engineers.
What are embeddings trying to solve?
Who hasn’t struggled when searching on an e‑commerce clothing website for something like:

And getting as a result:

But then when manually scrolling through all categories you come across with:

And you think: Are you kidding me?
Well sadly no one is kidding you, it’s just that the search engine is trying to match the characters of the search query with the characters on the product’s name or description (it’s a little bit more refined than that, but let’s keep it simple):
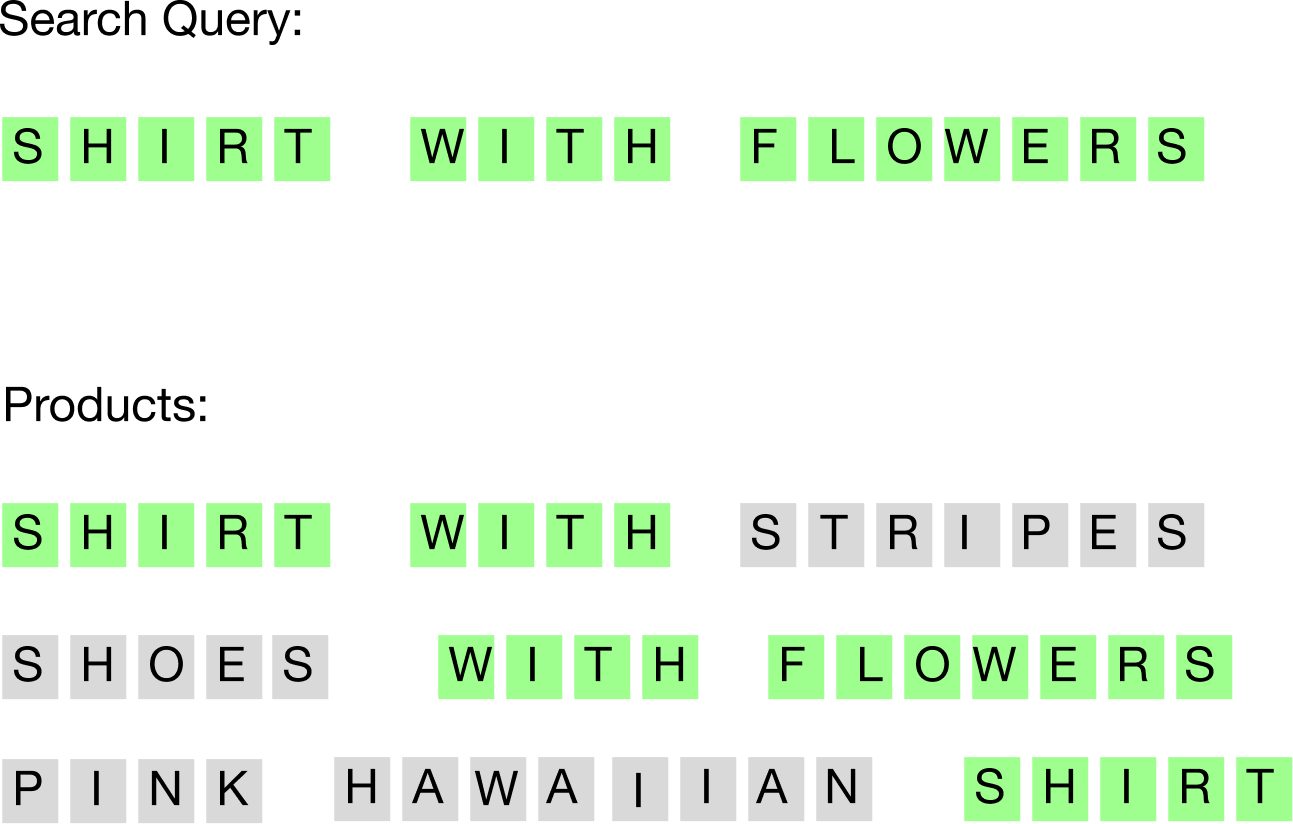
This has been the only way of doing search for a long time. Some inspired engineers came up with ways of mitigating the pain, by for example manually putting keywords in the product description to try to capture more character sequence matching:

Now search queries containing “classic”, “white”, “flowers”, “holidays” or “beach” will likely return the “Pink Hawaiian Shirt”.
Can you spot the issue such approaches? Try to do it for a catalog of 500 products and tell me then.
But… Why is it such a hassle? Because it inherently differs from the way we, humans, communicate. We rely heavily on meaning and context, not in specific letters and words present on a sentence. For us “Hawaiian Shirt” is a “Shirt with flowers”, without having to give much more specification.
Well luckily there’s a new way of doing this: Let me introduce you to semantic search with the help of embeddings.
How do embeddings work?
Note: I’m skipping the embeddings definition on purpose to not scare away the few curious readers that made it so far with the classic “highly dimensional vector space … latent representation … cosine difference ….”.
Embeddings try to match how humans understand concepts by giving close numbers to things that have similar meaning:

See that “banana” is quite close to “apple” and “yellow”, but very far from “car” and “universe”. The number below is what we call the embedding of the term on top.
And the best is: there’s a “magic box” called embedding model where you put in the term and it spits the number. This “magic” is actually where AI steps in, but you don’t have to worry about it.
Coming back to the previous example, instead of matching characters or keywords, we can compare the embeddings of the products and the search query.

Voilá! Any e-commerce or search-like functionality could use this “magic boxes” to highly improve search conversion and give your customers the feeling of “being understood”.
What else can we do with embeddings?
This is where it starts to get very exciting, we now have a way of translating language into math, so we can apply powerful algebraic operations to achieve outstanding actions. We will slowly dive deeper into engineering ground, so keep your eyes wide open!
Clustering & Classification
Given that, following the previous example, articles are translated into numbers, we can group the ones that are similar. We engineers like to use the fancy word “clustering” for it.
To describe better how it could benefit you, let’s use 2 numbers to represent each embedding instead of 1:
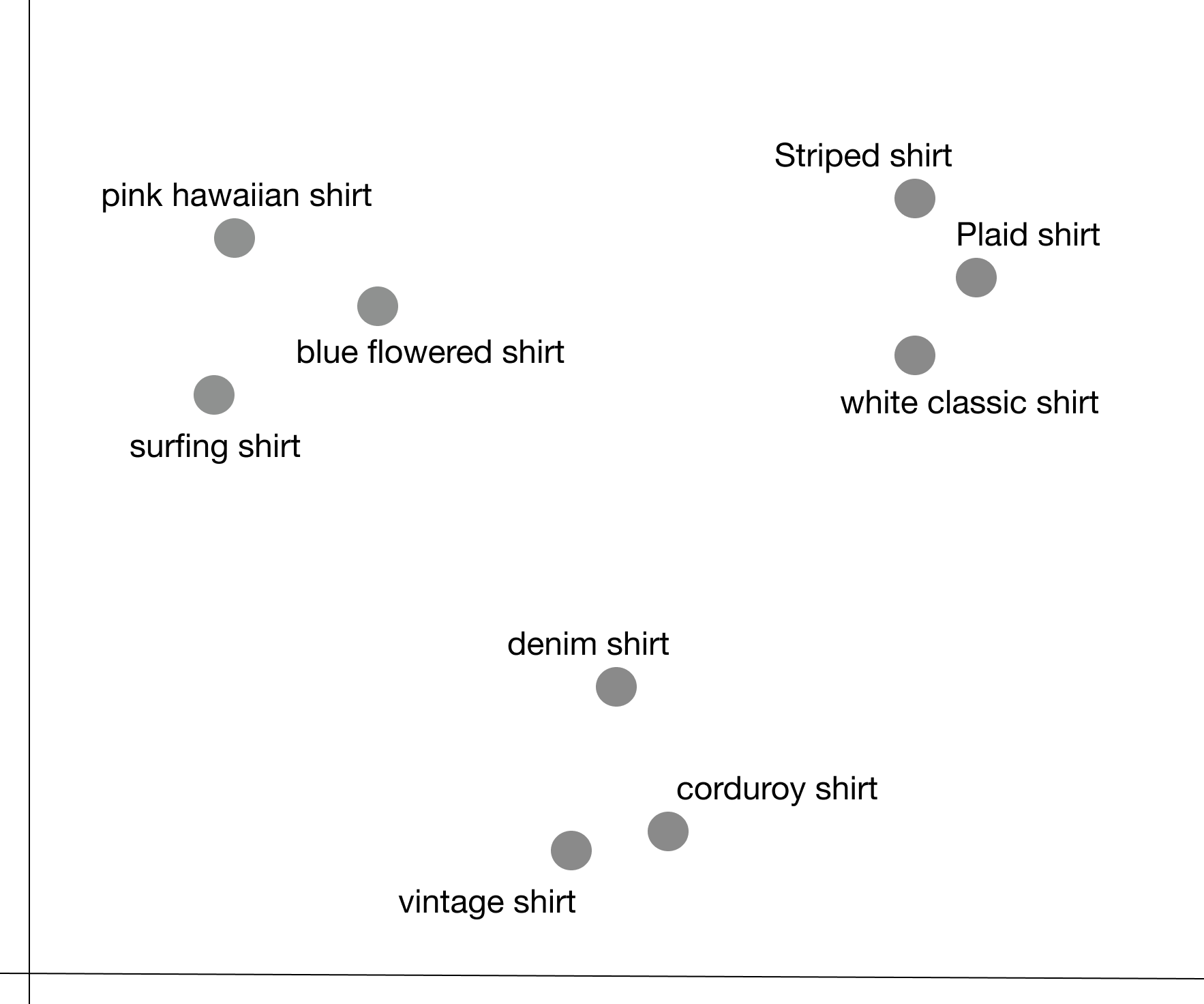
By applying some mathematic operator we can automatically group the articles into:
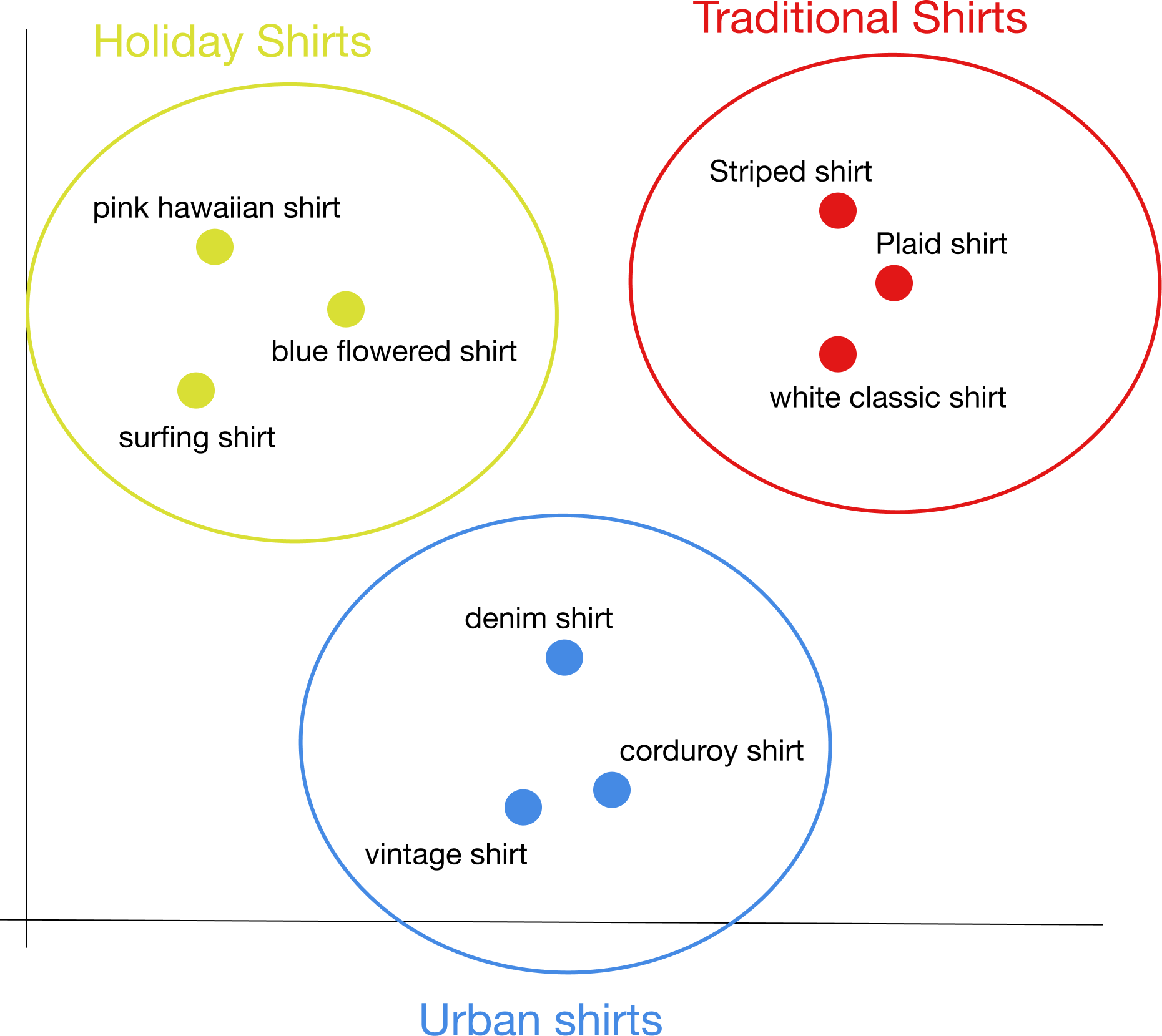
Do you see what this could enable for your business?
- Automatically extract optimal categories/hierarchies from your catalog
- Create dynamic facets/ filters on your search result page for users to narrow down the results
- Recommend similar articles when on an articles page.
- Identify weak or overcrowded groups of articles in your offering.
- Identify similar articles in your catalog for shared pricing and positioning strategies.
- And so much more! Our creativity is the limit
Visualisation & Analysis
Now that we can visualise the catalog in a regular 2-dimension plot, we can start analysing patterns! This could be critical for analysing for example user search patterns and catalog blind-spots better.
Let me show you a clear example. Given the catalog used in the example above, you could add the embeddings of the non-converting search queries to it:
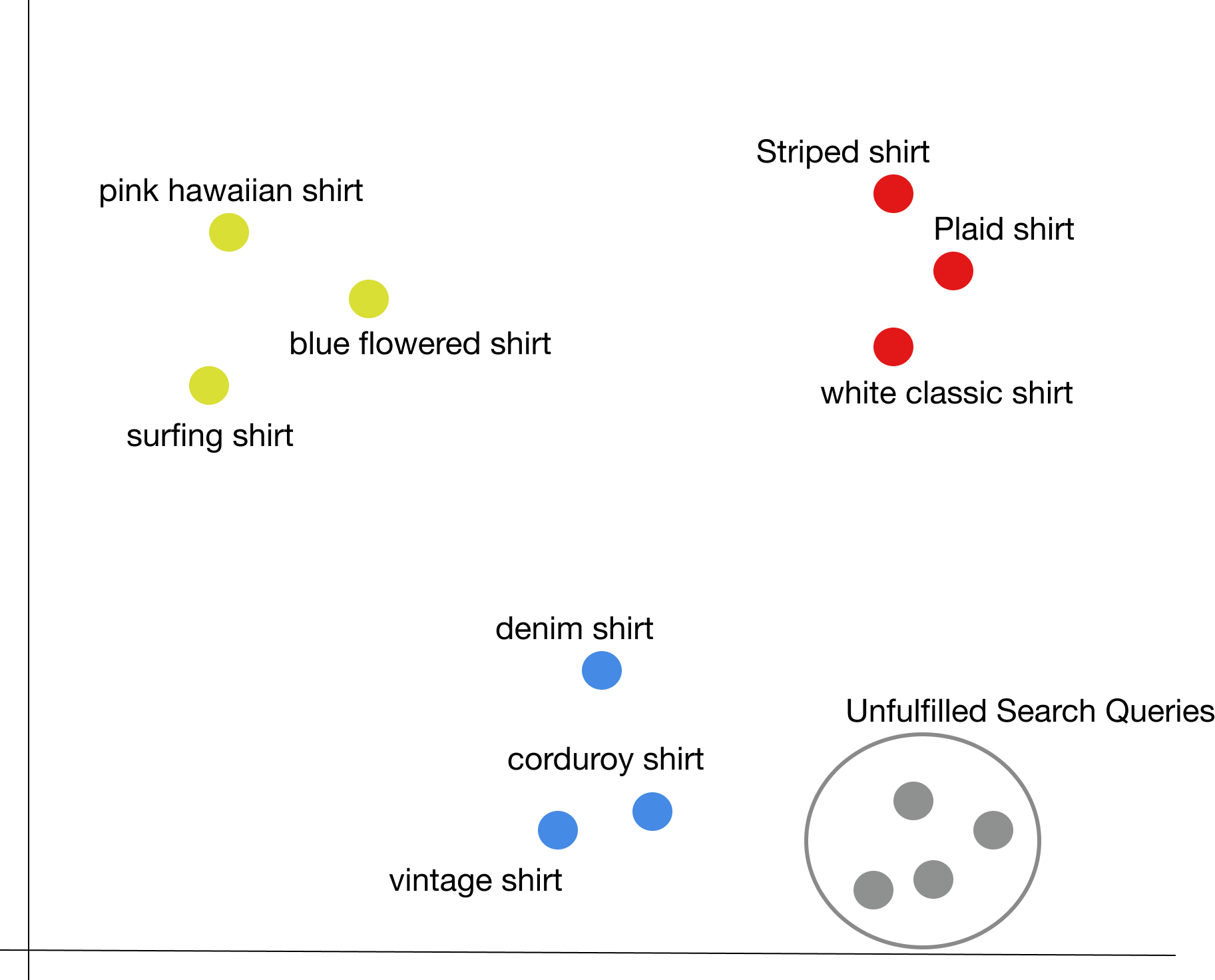
Hmmm, it seems that clients are searching for things similar to urban shirts but they’re finding nothing interesting. This could be a great business lead! You can afterwards deep dive into some of those queries to understand the underlying category you are missing and take action.
Document Retrieval
If you don’t have an e-commerce like business you can still leverage this technology. The state-of-the-art embedding models can work with single words, phrases, paragraphs and even whole documents.
This means that you can very easily search through a big set of documents and content, and in a blink of an eye extract the exact passages that you need with plain human language.
Let’s use a real example fjord has worked with, a classic law firm. Lawyers usually need to search the jurisprudence that correlates with a very specific case. This means searching over millions of old cases, each with a lot of inner documents, looking for the ones that are somehow similar to the case they’re dealing with. A true nightmare.
Let’s use the power of embeddings to solve it! First we pass all our documents through the “magic box”, getting a “number” out for each. Let’s plot it on the 2-dimension grid once more:

We can then ask for cases related to a specific topic, such as “Indigenous rights violated on the Patagonia region”. Just pass the question through the same “magic-box” and let the system retrieve the closest document where, once more, “close” refer to similar meaning:
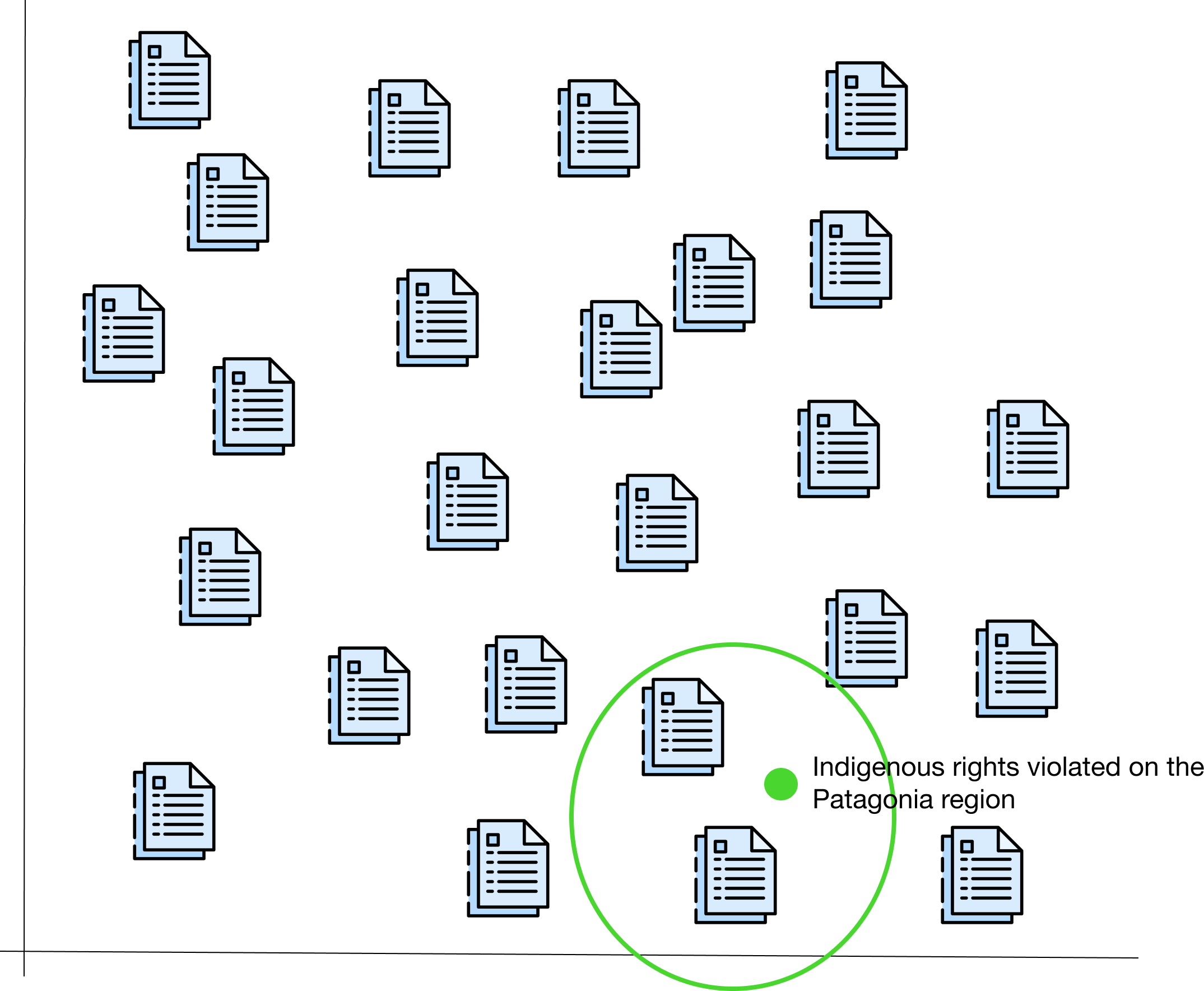
Hours of research saved with the power of embeddings and semantic search!
Once more, the applications of this technology are endless, and fjord can guide you through the right tool for the job.
For the curious minds, this is exactly what is done in RAG to enhance the performance of LLMs by supplying relevant document corpuses as context to the prompt. We will dive into this in a follow-up case study.
Multimodal embeddings
On the frontier of this technology lies the multimodal space. This means images, audios, text and videos having comparable embeddings.
This is extremely powerful, cause you can apply all what we talked about before within and across all these modalities. For example:
- Search for images, videos or audios with human languages, completely based on what’s inside the file.
- Compare and cluster images or videos, think of all the recommendation and analysis power unblocked by it.
So what’s the catch?
The catch is on our side, this requires a lot of data and software engineering to work well. Why?
-
The embeddings are not just numbers, they are vectors. Think of them as a list of numbers with more than a thousand elements. Calculating the similarity between numbers (difference) is way easier than with vectors (distance/orientation in space).
-
Embedding models, as magical as they sound, are not perfect. In the midst of it all some weird results can pop-up, i.e. “banana” closer to “red” than “yellow”. To make sure results are correct and consistent, you must filter the search results with another AI model - the ReRanker- to show only the right retrieved articles to the user.
-
There are some cases where keyword matching, the good old fella, is useful. Think for example on brand names, where is someone searches “Coca-Cola” then want “Coca-Cola” and not “Pepsi”. That’s why the sweet-spot is when both approaches are used, and then results are combined and re-ranked. As you can imagine, this brings some engineering overhead.
-
Speed and latency are very important when dealing with Search, every small part of the system must be optimised to its limit to give the “instant” feeling to the users. Embedding the query, calculating the algebraic distance to thousands of other embeddings, retrieving the closest one, filtering out the bad results and displaying the good ones in a few milliseconds.
-
Embeddings need to be always updated, if a title or description changes, a new article is added or one is deleted, you must ensure that things are re-calculated to keep on having meaningful results.
-
Embeddings need to live in special databases called “vector databases”. So it adds one more component to the system.
-
The embedding models, a.k.a “magic-boxes”, are always improving. You must keep researching and updating your system to squeeze as much precision and recall as possible.
-
When you are on a niche industry, with specific vocabulary and jargon, the general purpose embedding models stop being useful. In those scenarios the embedding model must be fine-tuned, re-taught with new related data, to become specialized on the topic in matter.
At fjord technology we know how to navigate through these complexities so that you and your customers just enjoy the benefits.
Want to learn more about the technologies mentioned?
Check fjord’s favourite resources: